模型训练、评估和推理流程
准备数据集
下载数据
如需要训练 COCO 数据集, 您可以在 COCO官方网站 下载图片数据, 然后在这里下载转换成 YOLO 格式的标签文件;
如需要训练 VOC 数据集,同样需要先下载对应的图片数据和标签文件,可从下面的链接下载。
| dataset | url | size | images |
|---|---|---|---|
| VOC2007 trainval | download zip | 446MB | 5012 |
| VOC2007 test | download zip | 438MB | 4953 |
| VOC2012 trainval | download zip | 1.95GB | 17126 |
YOLO 格式转换
如果标签文件不是 YOLO 格式,需要先转换成 YOLO 格式;
YOLO 格式定义:
一张图片对应一个标签文件,且标注信息的格式如下所示:
# 类别id 中心点x坐标 中心点y坐标 目标框宽度 目标框高度
0 0.300926 0.617063 0.601852 0.765873
1 0.575 0.319531 0.4 0.551562
每一行代表一个目标框信息;类别 id 从 0 开始;
目标框的坐标需要进行归一化,如果标注信息为原始像素值,中心点x坐标 和 目标框宽度 需要除以 图像宽度 做归一化,中心点y坐标 和 目标框高度 需要除以 图像高度 做归一化。
YOLO 格式转换:
对于如 VOC 的 xml 格式标注文件,我们提供了转换成 YOLO 格式的脚本。
python yolov6/data/voc2yolo.py --voc_path your_path/to/VOCdevkit
此外,我们还提供了可视化脚本,可用于检查数据集的标注信息是否正确。
python yolov6/data/vis_dataset.py --img_dir your_path/to/VOCdevkit/images/train --label_dir your_path/to/VOCdevkit/labels/train --class_names ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor']
组织文件夹
确保您的数据集按照下面这种格式来组织;
# COCO 数据集
├── coco
│ ├── annotations
│ │ ├── instances_train2017.json
│ │ └── instances_val2017.json
│ ├── images
│ │ ├── train2017
│ │ └── val2017
│ ├── labels
│ │ ├── train2017
│ │ ├── val2017
# VOC 数据集
# 训练集组成:VOC2007 和 VOC2012 train+val(16551)
# 验证集组成:VOC2007 test(4952)
VOCdevkit
├── images
├── labels
├── voc_07_12 #转换成YOLO格式的数据集文件夹
│ ├── images
│ │ ├── train
│ │ └── val
│ └── labels
│ ├── train
│ └── val
├── VOC2007
│ ├── Annotations
│ ├── ImageSets
│ ├── JPEGImages
│ ├── SegmentationClass
│ └── SegmentationObject
└── VOC2012
├── Annotations
├── ImageSets
├── JPEGImages
├── SegmentationClass
└── SegmentationObject
准备配置文件
创建数据集配置文件
我们提供了一些针对 COCO 数据集、VOC数据集及自定义数据集示例配置文件。 (当前仅支持该格式的数据集读取,后续会继续支持更多的数据集组织方式。)
1) 需要将数据集路径调整为您机器上所在的路径,建议用绝对路径;train/val 路径必填,test 路径选填。
2) 如果是 非COCO 数据集,需要将 is_coco 设置为 False,代码中会根据此标志参数判断是否需要将数据集标签格式转换为COCO格式,以便于模型评估采用 pycocotools 时调用。
选择网络配置文件
1) 如果是训练 COCO 数据集或与 COCO 差异较大的数据集,建议选用 yolov6n(/s/m/l).py 配置文件;
2) 如果是训练 自定义数据集,建议选用 yolov6n(/s/m/l)_finetune.py 配置文件;
关于配置文件的参数定义及解析,请参考[配置文件学习](配置文件学习.md)
模型训练
这里以训练 YOLOv6-S 模型为例:
单卡训练
# P5 models
python tools/train.py --batch 32 --conf configs/yolov6s_finetune.py --data data/dataset.yaml --fuse_ab --device 0
# P6 models
python tools/train.py --batch 32 --conf configs/yolov6s6_finetune.py --data data/dataset.yaml --img 1280 --device 0
多卡训练(推荐使用 DDP 模式)
# P5 models
python -m torch.distributed.launch --nproc_per_node 8 tools/train.py --batch 256 --conf configs/yolov6s_finetune.py --data data/dataset.yaml --fuse_ab --device 0,1,2,3,4,5,6,7
# P6 models
python -m torch.distributed.launch --nproc_per_node 8 tools/train.py --batch 128 --conf configs/yolov6s6_finetune.py --data data/dataset.yaml --img 1280 --device 0,1,2,3,4,5,6,7
关键参数说明:(可在train.py里查看所有参数定义)
- fuse_ab: 增加anchor-based预测分支并开启锚点辅助训练模式 (P6模型暂不支持此功能)
- conf: 定义网络和超参的配置文件,如果是训练自定义数据集,使用后缀带finetune的配置文件,并在配置文件pretrained参数指定预训练模型权重的路径;
- batch: 训练数据批大小,如果显卡内存不足,可适当调低该值;
- check-images 和 check-labels: 用于初始化数据集时检查图片和标签文件格式是否正确,并生成缓存文件,一般首次训练或由于数据集问题导致训练曾经中断而再次训练时需要添加这两个参数;
- write_trainbatch_tb: 用于在tensorboard可视化训练数据集的预测结果,对训练速度稍有影响,根据个人需要添加;
- distill: 开启logit蒸馏训练,搭配teacher_model_path参数共同使用,通过teacher_model_path参数指定教师网络的模型权重路径;需要先完成教师网络的训练后使用;
- distill_feat:开启feat蒸馏训练,仅在量化感知训练时与distill参数同时使用,常规自蒸馏训练默认不开启;
- resume: 用于上一次训练被中断后需要恢复训练使用;
如果需要在 COCO 数据集上 复现 我们的精度指标,请参考以下配置(可展开)
YOLOv6-N 🔽
# Step 1: Training a base model
# Be sure to open use_dfl mode in config file (use_dfl=True, reg_max=16)
python -m torch.distributed.launch --nproc_per_node 8 tools/train.py \
--batch 128 \
--conf configs/yolov6n.py \
--data data/coco.yaml \
--epoch 300 \
--fuse_ab \
--device 0,1,2,3,4,5,6,7 \
--name yolov6n_coco
# Step 2: Self-distillation training
python -m torch.distributed.launch --nproc_per_node 8 tools/train.py \
--batch 128 \
--conf configs/yolov6n.py \
--data data/coco.yaml \
--epoch 300 \
--device 0,1,2,3,4,5,6,7 \
--distill \
--teacher_model_path runs/train/yolov6n_coco/weights/best_ckpt.pt \
--name yolov6n_coco
YOLOv6-S/M/L 🔽
# Step 1: Training a base model
# Be sure to open use_dfl mode in config file (use_dfl=True, reg_max=16)
python -m torch.distributed.launch --nproc_per_node 8 tools/train.py \
--batch 256 \
--conf configs/yolov6s.py \ # yolov6m/yolov6l
--data data/coco.yaml \
--epoch 300 \
--fuse_ab \
--device 0,1,2,3,4,5,6,7 \
--name yolov6s_coco # yolov6m_coco/yolov6l_coco
# Step 2: Self-distillation training
python -m torch.distributed.launch --nproc_per_node 8 tools/train.py \
--batch 256 \ # 128 for distillation of yolov6l
--conf configs/yolov6s.py \ # yolov6m/yolov6l
--data data/coco.yaml \
--epoch 300 \
--device 0,1,2,3,4,5,6,7 \
--distill \
--teacher_model_path runs/train/yolov6s_coco/weights/best_ckpt.pt \
--name yolov6s_coco # yolov6m_coco/yolov6l_coco
YOLOv6-N6/S6 🔽
python -m torch.distributed.launch --nproc_per_node 8 tools/train.py \
--batch 128 \
--img 1280 \
--conf configs/yolov6s6.py \ # yolov6n6
--data data/coco.yaml \
--epoch 300 \
--bs_per_gpu 16 \
--device 0,1,2,3,4,5,6,7 \
--name yolov6s6_coco # yolov6n6_coco
YOLOv6-M6/L6 🔽
# Step 1: Training a base model
python -m torch.distributed.launch --nproc_per_node 8 tools/train.py \
--batch 128 \
--conf configs/yolov6l6.py \ # yolov6m6
--data data/coco.yaml \
--epoch 300 \
--bs_per_gpu 16 \
--device 0,1,2,3,4,5,6,7 \
--name yolov6l6_coco # yolov6m6_coco
# Step 2: Self-distillation training
python -m torch.distributed.launch --nproc_per_node 8 tools/train.py \
--batch 128 \
--conf configs/yolov6l6.py \ # yolov6m6
--data data/coco.yaml \
--epoch 300 \
--bs_per_gpu 16 \
--device 0,1,2,3,4,5,6,7 \
--distill \
--teacher_model_path runs/train/yolov6l6_coco/weights/best_ckpt.pt \
--name yolov6l6_coco # yolov6m6_coco
恢复训练
如果您的训练进程中断了,您可以这样恢复先前的训练进程。
# 单卡训练
python tools/train.py --resume
# 多卡训练
python -m torch.distributed.launch --nproc_per_node 8 tools/train.py --resume
上面的命令将自动在 YOLOv6 当前训练保存目录中找到最近保存的模型,然后恢复训练。
您也可以通过 --resume 参数指定要恢复的模型路径,这种方式会从您提供的模型路径恢复训练。
# 请将 /path/to/your/checkpoint/path 替换为您要恢复训练的模型权重路径
--resume /path/to/your/checkpoint/path
训练过程可视化
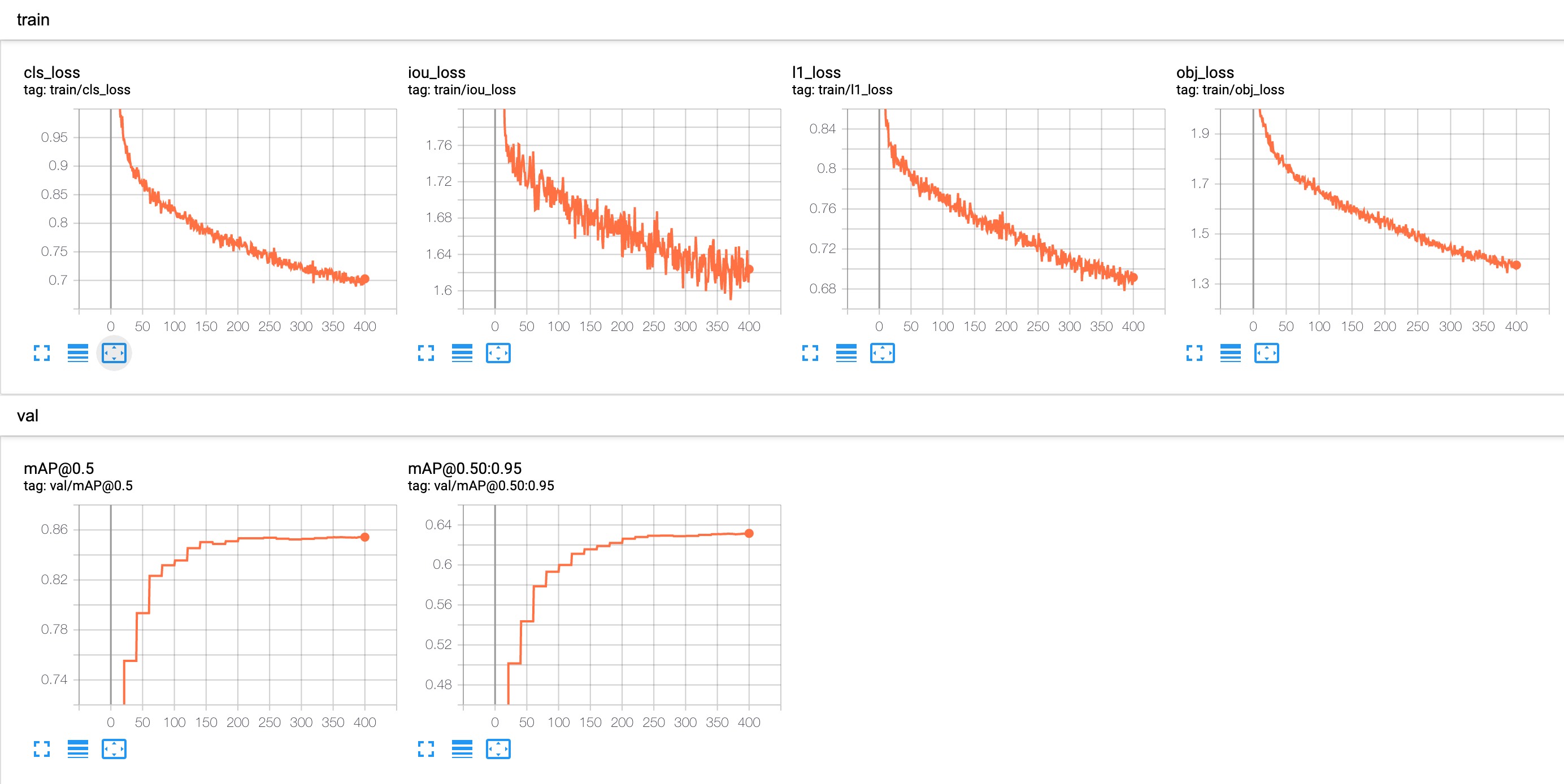
使用 tensorboard 可视化 训练数据/ 验证数据 的预测结果 以及 loss/mAP 曲线,命令如下:
tensorboard --logdir=your_path/to/log
打开对应的网页之后,可以看到 loss/mAP 曲线;
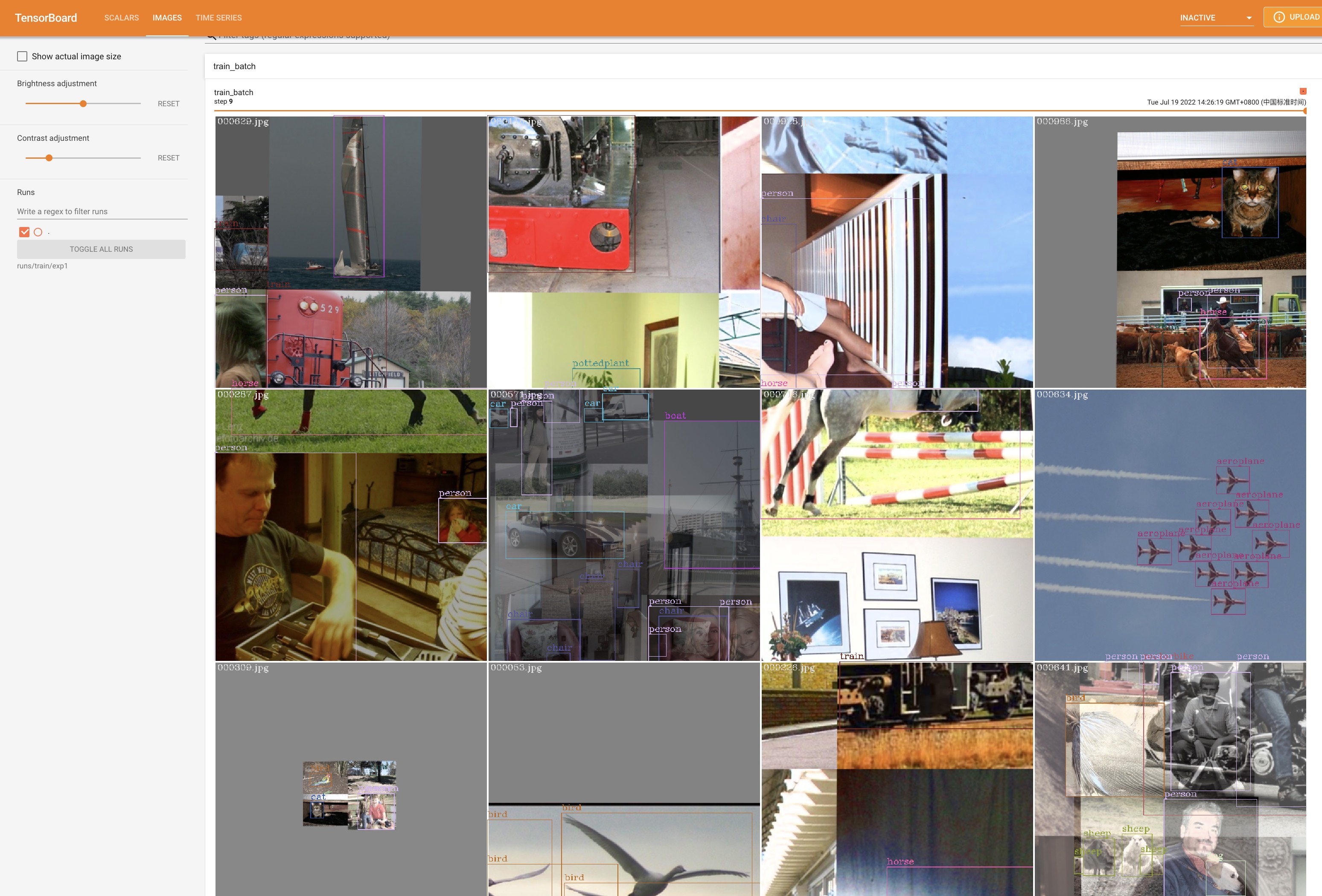
如果需要可视化训练数据的预测结果,需要在训练启动命令中添加参数 --write_trainbatch_tb
模型评估
模型在验证集/测试集上进行精度/速度评估:
python tools/eval.py --data data/coco.yaml --batch 32 --weights yolov6s.pt --task val/test/speed
关键参数说明:(可在eval.py里查看所有参数定义)
- task: 通过task参数指定评估任务,val表示在验证集上评估精度,test表示在测试集上评估精度,speed表示在验证集上评估速度;
- do_coco_metric: 设置 True / False 来打开或关闭 pycocotools 的评估,一般用此方式评估的结果较准确,但速度稍慢,默认打开;
- do_pr_metric: 设置 True / False 来显示或不显示精度和召回的指标,默认关闭,可根据个人需要开启;
- reproduce_640_eval: 可复现COCO上的精度指标所使用的配置,具体可在[eval_640_repro.py](https://github.com/meituan/YOLOv6/blob/main/configs/experiment/yolov6n_with_eval_params.py)此配置文件中查看相关的参数配置;
- verbose: 如果要打印每一个类别的精度信息,可设置为 True;
- config-file: 选用参数,用于指定包含所有评估参数的配置文件,具体可见[yolov6n_with_eval_params.py](https://github.com/meituan/YOLOv6/blob/main/configs/experiment/yolov6n_with_eval_params.py) 示例文件;
在 COCO val2017 数据集上复现我们的结果(输入分辨率 640x640 或 1280x1280)
# P5 models
python tools/eval.py --data data/coco.yaml --batch 32 --weights yolov6s.pt --task val --reproduce_640_eval
# P6 models
python tools/eval.py --data data/coco.yaml --batch 32 --weights yolov6s6.pt --task val --reproduce_640_eval --img 1280
模型推理
步骤 0. 从 YOLOv6官方github 下载一个训练好的模型权重文件,或选择您自己训练的模型;
步骤 1. 通过 tools/infer.py文件进行推理。
# P5 models
python tools/infer.py --weights yolov6s.pt --source img.jpg / imgdir / video.mp4
# P6 models
python tools/infer.py --weights yolov6s6.pt --img-size 1280 1280 --source img.jpg / imgdir / video.mp4
关键参数说明:(可在eval.py里查看所有参数定义)
- source: 用于指定需要推理的图片或视频,支持批量图片推理,可指定图片路径,数据集所在文件夹,视频路径等;
- img-size: 用于指定推理的图像尺寸(高,宽),如(1280,1280),默认为(640,640);
- yaml: 用于指定数据集配置文件,主要是获取配置文件中的class_names以便于可视化时加上类别信息;
- conf: 设置推理采用的分数阈值,默认为0.4;
- iou: 设置推理采用的iou阈值,默认为0.45;
- save-img: 保存检测框可视化后的图片,默认打开;
- save-txt: 保存包括检测框的信息的txt文件,默认关闭;
- view-img: 展示检测框可视化后的图片,默认关闭;
- classes: 指定可视化的类别,如无指定,默认所有类别均被可视化;
- hide-labels: 可视化目标框时隐藏类别信息,默认关闭;
- hide-conf: 可视化目标框时隐藏预测分数信息,默认关闭;
- name: 指定保存可视化结果的文件夹,会自动创建,默认为‘exp’。
运行后,在runs/inference/exp目录下能看到对应的可视化结果。
